So it has been a few days since Part 2, where I promised I’d talk about some issues that go with using pointers in shared memory, initial cache setup, and my arbitrary methods I use to handle various scenarios.
Pointing to things in shared memory
First I’ll talk about pointers. Essentially all you need to know about them is that a pointer holds a memory address, namely the address of the data you’re really interested in.
Now, every process in modern operating systems has its own “address space”, which defines where things are in memory. So, memory addresses in process 1 have no relation to addresses used in process 2, or any other process.
What this means for shared memory algorithms is that you cannot use normal pointers, since they rely on pointing to a specific spot in a process’s address space. See below for an example:
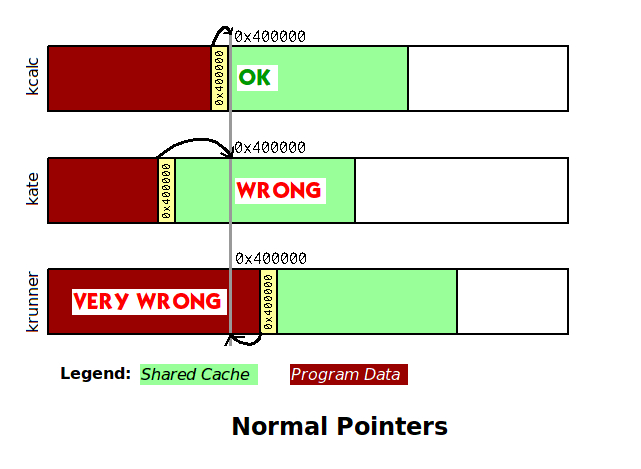
Three KSharedDataCache-using processes are running, and let’s say that kcalc was the first to create that cache, so the pointers are created from the perspective of kcalc’s address space. If KSharedDataCache used normal pointers to point to the data in the cache (from the cache header) then things would fail to work right in kate where we point into the middle of the data. The case of krunner is even worse, as we point into the krunner process’s private data!
The solution is not too hard. The memory map call that creates the connection will tell you where the connection starts. So instead of saying “the data is at address 0x400000”, use pointers that say “the data is 1024 bytes past the start”. These are called offsets. For example, the pthread library that is standard in POSIX could use this type of technique to implement “process-shared” mutexes (mutexes are by default merely thread-shared).
Initial cache setup
Taking that first step in creating a cache is hard. Once the cache is setup we can rely on having some means of locking, entry tables that are setup, and other niceties. Creating that in the face of race conditions is another matter though.
My decision to use pthreads for the mutex made this part harder than it could have been otherwise, as the mutex has to be stored with the cache. But you can’t use the mutex without initializing it first (remember that pthread mutexes default to not being process-shared). If two processes try to create a non-existing cache at the same time, they would both try to initialize the mutex, and the process that initializes the mutex the second time could potentially cause logic errors in the first process.
So, I went with a simpler solution for this rare case: A spinlock, using Qt’s built-in atomic operations. It is not quite a pure spinlock because there are a couple of possibilities (numbered as they are in the code):
Case 0 is that the cache has just been created, without ever having been attached to. (0 because that is the default value for an initially empty file that has just been mapped into shared memory).
Case 1 is that there is a process which has noticed that the cache is not initialized, and is initializing it (in other words, it atomically switched the 0 flag to 1). This is a locking condition: No other process will attempt to initialize the cache. But the cache is not initialized yet!
Case 2 occurs when the cache has been finally initialized, and can have the standard locks and methods used. To access a cache that is in this condition you must use the cache mutex.
I don’t use a spinlock all the time because my implementation does not do any magical non-locking algorithms, and therefore some operations might take some significant time with the lock held. Using a mutex allows threads that are waiting to sleep and save CPU and battery power, which would not work with a spinlock.
Cache handling
Any cache needs a method of deciding when to remove old entries. This is especially vital for hash-based caches that use probing, like KSharedDataCache, where allowing the cache to reach maximum capacity will make it very slow since probing becomes both more common, and more lengthy. I use several techniques to try to get rid of old entries. I make no promises as to their effectiveness, but I felt it was better to try something than to do nothing. The techniques are:
- Limited Quadratic Probing: One standard method of handling items that hash to the same location in a hash table is to use “probing”, where the insertion/find algorithms look at the next entry, then the next, and so on until a free spot is found. Obviously this takes longer, especially if the hash function tends to make entries cluster anyways. In the case of KSharedDataCache it’s perfectly acceptable to simply give up after a certain number of attempts, and I quite willingly do so (but see the next technique). On the other hand if you can avoid colliding you don’t have to worry about finding empty spots, so to that end I use the “FNV” hash function by Fowler, Yo, and Noll.
- Ramped Entry Aging™: The basic idea is that as the amount of entries in the cache goes up, it becomes more likely that the insertion method will, instead of probing past a colliding entry, artificially decrease its use count, and kick it out if it becomes unused. There are competing effects here: There’s no point having a cache if you’re not going to employ it, so this aging never happens if the cache is lightly loaded. On the other hand entries that get added to the cache and only ever used once could cause collisions for weeks afterwards in the long-lived scenarios I envision so it is important to make entries justify their use. So as the cache load increases, there is a higher and higher chance of entries being evicted if unused. I simply divide the use count in half, so an entry can be quickly evicted even if used a million times a month ago.
- Collateral Evictions®: In the event that the first two options don’t work, then some entries have to be kicked out to make room for new ones. This process is called eviction. In my Collateral Evictions plan, anytime we kick entries out, we kick even more entries out on top of that (I chose twice as many, for no particular reason). The idea is that if we’re running of out space we’ll probably have to kick someone else out on the very next insert call anyways, so since it’s a time-consuming operation we might as well make it effective. The exact entries that get kicked out are decided based on the developer-configurable eviction policy.
Next time I’ll talk about defragmentation, porting KIconLoader, and any other random things I can think up. I hope it hasn’t been deathly boring so far!